主题
MySQL 待完善
SQL 语法
count 主键和 count 非主键结果会不同吗?
不一定相同。
- 主键是非 NULL 的,count 主键会返回所有条数
- 非主键可能存在 NULL值,会返回指定列的非 NULL 条数
MySQL 内连接、外连接有什么区别?
内外连接都用于连表查询。
- 内连接的结果是两个查询的交集。
- 外连接的结果是其中一个结果和两个结果的交集的并集部分,未匹配到的用 NULL 填充。
外连接时 on 和 where 过滤条件区别?
在内连接中,on 和 where 相同。
在外连接中,on 是连接条件,where 是过滤条件。
having 与 where 的区别?
where 在 group by 分组之前过滤
having 在 group by 分组之后过滤
delete、drop、truncate 有什么区别?
- delete:删除表的数据,逻辑删除,可以回滚。
- drop:直接删除表和表结构,不能回滚
- truncate:删除表中所有记录,不能回滚
联合查询中 union 和 union all 的区别是什么?
- UNION:在合并结果集后会自动别除重复的行。
- UNION ALL:则会保留所有的重复行,不会进行去重操作。
数据库三大范式是什么?
- 第一范式:属性不可再分
- 第二范式:有主键,非主键字段依赖主键
- 第三范式:非主键字段不能相互依赖
开发不必满足三大范式,可以设计冗余字段
count(*) 性能比 count(1) 好吗?
两者性能相同。MySQL 中,count(*) 会被优化器优化成 count(0)。
count(*) = count(1) > count(主键) > count(非索引字段)
sql 语句执行优先级
- FROM:首先从指定的表中获取数据。
- JOIN:如果有连接操作,会在 FROM 之后进行。
- WHERE:对获取的数据进行过滤。
- GROUP BY:在过滤后的数据上进行分组。
- HAVING:对分组后的数据进行过滤。
- SELECT:选择需要的列。
- DISTINCT:去除重复的结果。
- ORDER BY:对结果进行排序。
- LIMIT/OFFSET:限制返回的行数。
MySQL 的约束有什么?
- 主键约束
- 外键约束
- 默认约束
- 唯一约束
- 非空约束
存储引擎
执行一条 SQL 的全过程
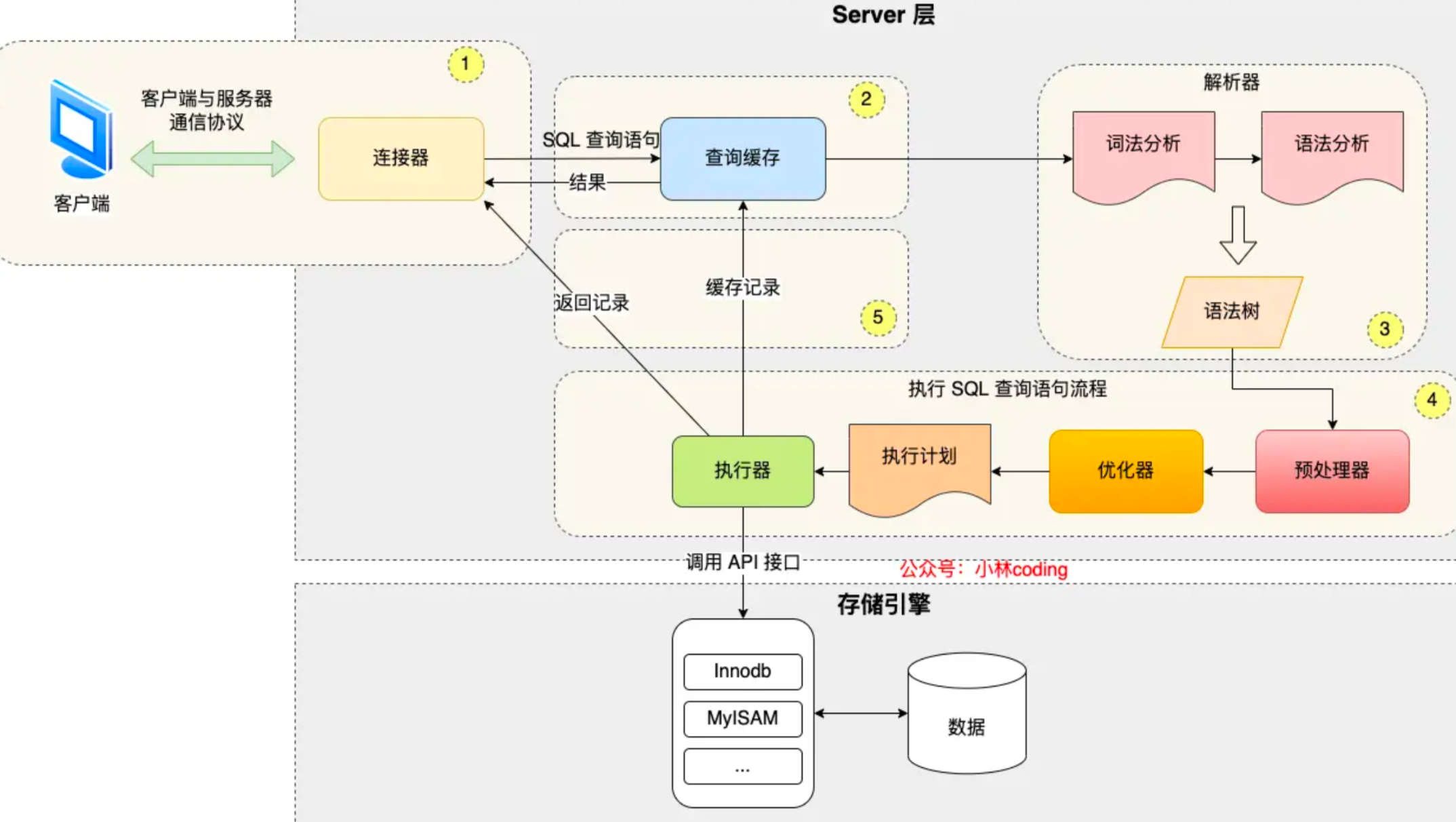
- 连接器:验证身份、接受SQL语句
- 查询缓存
- 解析器:SQL 语法分析
- 优化器:优化 SQL 语句
- 执行器:执行 SQL
MySQL 存储引擎有什么?
- InnoDB:MySQL 默认引擎,支持行级锁和事务
- MyISAM:不支持事务,只有表锁。适合读多写少
- Memory:存储在内存中,读写较快,但没有持久化
MyISAM 和 InnoDB 有什么区别?
- InnoDB 支持行级锁和事务,MyISAM 只有表锁,没有事务。
- InnoDB 将索引和数据存放在一起,B+ 树叶子结点存放数据;MyISAM 将索引和数据分开存储,B+ 树中存放数据地址。
❓哪个存储引擎的 count(*) 最快?
NULL 值是怎么存储的?
MySQL 每一行有 NULL 值列表,通过二进制标记为 NULL 值的列。
char 和 varchar 的区别
- char 是定长字符串,会使用空格填充
- varchar 是可变字符串,只存储实际占用和字符串长度
假如说一个字段是varchar(10),但它其实只有6个字节,那它在内存中占的存储空间是多少?在文件中占的存储空间是多少?
- 内存:10 字节。按照最大值分配内存
- 存储:6 字节 + 记录字符串长度的 1-2 字节
如果内存超大,MySQL 能代替 Redis 吗?
不能。
- MySQL 是为了磁盘存储而设计,优化主要为了减少磁盘 IO 的读写性能;Redis 是面向内存设计的数据库。
- MySQL 的所有数据结构都是 B+ 树,复杂度是 O(logn);Redis 具有多种数据结构,Hash 复杂度 O(1)。
- MySQL 更新为了保证事物隔离,需要加锁;Redis 更新不需要加锁。
索引结构
MySQL 索引有哪些?
- B+ 树索引:InnoDB 的默认索引
- 哈希索引
- 全文索引
InnoDB 引擎索引的数据结构是什么?
B+ 树索引
为什么使用 B+ 树?
- B+ 树是多叉树,平衡二叉树、红黑树是二叉树,层级更高,且需要频繁进行平衡,需要更多磁盘 IO
- 跳表的性能不稳定,极端情况会变成链表,且占用空间较大,需要多次磁盘 IO
- B 树所有节点都存放数据,B+ 树只有叶子节点才存放数据,对范围查询不友好,且读取索引时需要更多的内存和磁盘 IO。
- 哈希表不支持范围查询和排序
聚簇索引和非聚簇索引的区别?
- 聚簇索引通常是主键索引,叶子节点存放数据。
- 非聚簇索引通常是非主键的索引,叶子结点存放主键,需要回表查询。
❓insert 操作对 B+ 树结构的改变是怎么样的?
❓假如一张表有两千万的数据,B+树的高度是多少?怎么算的?
索引应用
MySQL 有什么索引?
- 主键索引
- 唯一索引
- 普通索引
- 联合索引:多字段联合查询
- 前缀索引:字符串前缀匹配
普通索引和唯一索引有什么区别?哪个更新性能更好?
普通索引的值可以重复,唯一索引的值具有唯一约束,不能重复。
普通索引性能更好。
普通索引更新完直接放在 change buffer 缓冲区;唯一索引需要磁盘 IO 验证唯一约束。
主键怎么设置?假如你不设置会怎么样?
设置列名后设置 primary key
不设置主键会使用第一个非 NULL 且唯一的列作为主键,如不存在会生成隐式 rowid 列作为主键。
索引的类型有那些
- 主键索引
- 唯一索引
- 联合索引
- 前缀索引
- 普通索引
为什么需要创建索引?
- 将全表扫描的 O(n) 优化成 B+ 树的 O(logn)
- 将随机 IO 转化成顺序 IO
- 索引可以帮助 MySQL 避免外部排序和使用临时表
除了索引,还能怎么优化数据库?
- 对频繁被查询的条件添加索引
- 避免使用
select *,尽量使用具体列名 - 使用分页
- 对于大量添加、更新或删除,使用批量处理优化
- 查询时避免使用函数
选择什么字段作为索引?
- 值的重复性较低、NULL 值较少
- 常作为条件查询、分组、排序
索引越多越好吗?
不是的。
- 索引占用空间,每个索引都有独立的 B+ 树。
- 更新和插入需要维护所有 B+ 树,降低写入性能。
什么情况不用索引更好?
- 写多读少
- 值的重复度高
为什么主键需要自增
非顺序主键写入会导致B+树页分裂,产生空间碎片
索引怎么优化?
- 使用联合索引进行覆盖索引优化
- 避免查询时索引失效
- 主键索引自增
- 对于长字符串使用前缀索引
建立了索引一定会被用到吗?
- 索引失效:联合索引不满足最左匹配原则、非等的范围查询、使用函数或隐性转换、左侧模糊查询、两侧不全是索引时使用 or
- 数据库优化:因为索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不如全表扫描方便,此时索引就会失效。
纯数字的字符串不加引号会命中索引吗?
不会。会进行使用函数隐式转换,索引失效。
MySQL 8 的索引新特性
- 函数索引:解决函数会导致索引失效的问题
- 索引跳跃式扫描:不满足最左匹配原则也可以使用联合索引
建立联合索引有什么需要注意的?
将区分度大的字段放在最左侧
❓了解索引下推吗?什么情况下会下推到引擎去处理?
如果查询条件中包含索引列和非索引列,具体查询流程是什么样的?
先在索引列拿到主键 id,再回表过滤非索引列。
外键的优缺点?
- 优点:保证数据完整性和一致性
- 缺点:消耗数据库性能(还需要获取其他表的读锁)、外键能在业务层实现、无法用于分库分表场景
事务
MySQL 事务有什么特性?
- 原子性:undo log
- 一致性
- 隔离性:MVCC + 锁
- 持久性:redo log