主题
Redis 已完结
基础
什么是 Redis?
- Redis 是一个基于内存的数据库,属于 NoSQL。
- 具有多种数据结构:字符串、哈希、列表、集合、有序集合、bitmap等
Redis 的优势?
- 读写速度快
- 支持多种数据结构
- 具有多种功能:集群、数据持久化、队列
为什么用 Redis 作为 MySQL 缓存?
Redis 存储在内存,不需要磁盘 IO。可以提高访问速度。
Redis 作为旁路缓存,怎么保证缓存一致的?
在更新数据库时主动更新或删除缓存
Redis 作为旁路缓存时,是先删缓存还是先更新数据库?
先操作数据库,然后再删除缓存
避免其他线程在删除完缓存后,更新数据库前重建旧的缓存。
Redis 相比 Memcached 有哪些优势?
- 数据结构的支持:Redis 有多种数据结构,Memcached 仅支持简单字符串。
- 持久化:Redis 有 AOF 和 RDB 机制进行持久化,Memcached 只保存在内存中。
- Lua 支持:Redis 支持 Lua 脚本。
- 多线程:Redis 是单线程的,Memcached 是多线程,CPU 利用率较高。
Redis支持事务回滚吗?
不支持
Redis 的数据类型有什么?
- String
- Hash:唯一键值对(不排序的 Zset)
- List 列表:双端链表
- Set 集合:唯一的值
- Zset 有序集合:通过 score 排序的集合
Redis 过期数据的返回值?
返回 nil
String
set 一个已有的值会发生什么?
覆盖原有值
浮点数在 String 中用什么表示?
根据浮点数长度不同,使用 Raw 或 EMBSTR 编码
String 最大多大?
官网注明最大 512 MB
Redis 的字符串如何实现?
字符串底层是 String 对象。有三种编码方式:INT、RAW、EMBSTR。
- 整数使用 INT 编码,
ptr中直接存数值 - 小于阈值(44字节)的字符串使用 EMBSTR 编码,为 SDS 和 head 申请连续空间,单次申请效率更高。
- 大于阈值使用 RAW 编码,最大可存 512 MB
SDS 要有什么用?
SDS 是简单动态字符串
- SDS 包含字符串长度,效率更高
- SDS 预留部分空间,节约性能
- 不以
\0作为结束条件,二进制安全
SDS 编码阈值为什么是 44 字节?
Redis 使用 jemelloc 分配内存,jemelloc 以 64 字节为单位。Redis 对象头信息 16 字节、SDS 非内容部分 3 字节、字符串末尾 \0 1字节,剩余部分 44 字节。
List
List 是完全先入先出吗?
List 可以双端操作,不是完全的。
List 对象底层编码方式是什么?
- 3.2 版本之前:ZIPLIST 和 LINKEDLIST
- 3.2 版本以后:QUICKLIST 压缩列表组成的双向链表
- 7.0 版本以后:优化成 LISTPACK
ZIPLIST 是如何压缩数据的?
ZIPLIST 是连续内存空间,不产生内存碎片,不需要额外存放指针,节约内存。
ZIPLIST 下 List 可以从后往前遍历吗?
可以的,List 是双端队列。
ZIPLIST 头信息中存放最后一个节点的地址,节点存放前一个节点的长度,可以反向遍历。
在ZIPLIST数据结构下,查询节点个数的时间复杂度是多少?
ZIPLIST 头信息中有一个字段存放节点个数,2字节,最大为 65535。
所以长度在 65535 以内是 O(1),超过需要遍历 O(n)。
LINKEDLIST编码下,查询节点个数的时间复杂度是多少?
O(1)
LINKEDLIST 头信息中存有节点个数。
Set
Set 的编码方式
Set 有两种编码方式
- 存放的数据均为整数,且不超 512 个,使用 intset 编码
- 否则使用 Dict 字典编码
intset:特殊的整数数组。保证唯一且有序,使用二分查找。
Set 是有序的吗?
无序的。
对于 INTSET 编码的 Set 是有序的,使用 Dict 字典编码是无序的。
Hash
Hash 的编码是什么?
Hash 有两种编码方式。
- 对于元素较少且单个元素长度较小,使用 ZIPSET 编码。
- 否则使用 HashTable 编码
Hash 查找每个 key 的时间复杂度是多少?
- 对于 ZIPSET 编码,需要遍历,O(n)。
- 对于 HashTable 编码,O(1)。
HashTable 查找元素总数的复杂度?
O(1)
HashTable 头信息中有 used 字段。
一个数据在 HashTable 中的存储位置,是怎么计算的?
通过哈希函数算出哈希值,与掩码做与运算,获得索引值,也就是 HashTable 的存储位置。
HashTable 如何扩容?
通过渐进式 rehash 进行扩容。
- HashTable 有两个表指针,计算新的 size,并申请内存,将存放在 1 号表中。
- 每次 CRUD 时,都会把当前存储位置的旧表数据,重新计算哈希值,迁移到新表。
- 直至所有数据都迁移至一号表,释放 0 号表内存,并将 0 号表和 1 号表互换。
HashTable 扩容和缩容的条件?
扩容:无后台操作时,负载因子大于等于 1;后台有操作时,负载因子大于等于 5。
缩容:负载因子小于等于 0.1
Zset
Zset 底层有几种编码方式?
Zset 有两种编码:ZIPSET 和 跳表 + 字典。
- 当元素较少,且单个元素较小时,会使用 ZIPSET 编码。
- 否则使用跳表 SkipList 和字典 Dict 编码。
跳表查询节点总数的复杂度?
O(1)
跳表的头结点中存放了 length 字段。
跳表插入的时间复杂读
O(logn)
插入前需要查找插入位置,查找的复杂度是 O(logn)
跳表的节点层高是如何决定的?
使用随机函数计算层高,每加一层的概率是 25%,最高为 32 层。
ZSet 为什么不使用平衡树?
- 跳表的实现比平衡树简单
- 平衡树需要保持平衡,导致树的旋转。
- 对于区间遍历,跳表比平衡树更方便
Redis 的执行
Redis 是单线程还是多线程?
对于核心操作是单线程
对于其他模块有多线程参与,比如异步删除、解包回包等
解包:接收客户端请求并解析命令
回包:将命令执行结果发送回客户端
为什么 Redis 的核心功能使用单线程?
- Redis 是内存操作,多线程不会带来较大性能提升
- 多线程有上下文切换的成本和线程安全问题
为什么 Redis 单线程性能也很好?
- 内存操作,比磁盘 IO 速度快
- Redis 使用了高效的数据结构
- 采用单线程,减少上下文切换的成本,避免线程安全问题
- 使用了 IO 多路复用,可以同时监听多个 Socket
Redis 6.0 的多线程是默认开启的吗?主要负责哪里?
默认关闭的,可以修改配置文件开启。
多线程主要负责解包和回包,也就是 Socket 的的 IO 部分。
Redis 持久化
RDB 和 AOF 的本质区别是什么?
RDB 是保存快照,AOF 是追加日志。
- RDB 保存的是二进制数据,AOF 是文本数据。
- 宕机时,RDB 容易丢失更多数据,AOF 默认配置最多丢失 1s 的数据。
- RDB 是二进制数据,恢复速度比 AOF 更快。
- RDB 需要全量保存,操作较重;AOF 是追加数据,操作比较轻。
RDB 和 AOF 只能选择一个,怎么选择?
主要看应用场景。
- 能接受分钟级别的数据丢失,使用 RDB,获得更好的性能。
- 如果对数据安全性要求较高,使用 AOF。
RDB 的触发时机
- 执行
save、bgsave命令 - 根据配置的周期保存
- 全量同步
- Redis 关闭之前
AOF 混合存储是什么?
使用 RDB 将内存数据持久化到 AOF 文件,对于运行期间的操作,使用 AOF 追加写入。得到 AOF 和 RDB 组成的日志。
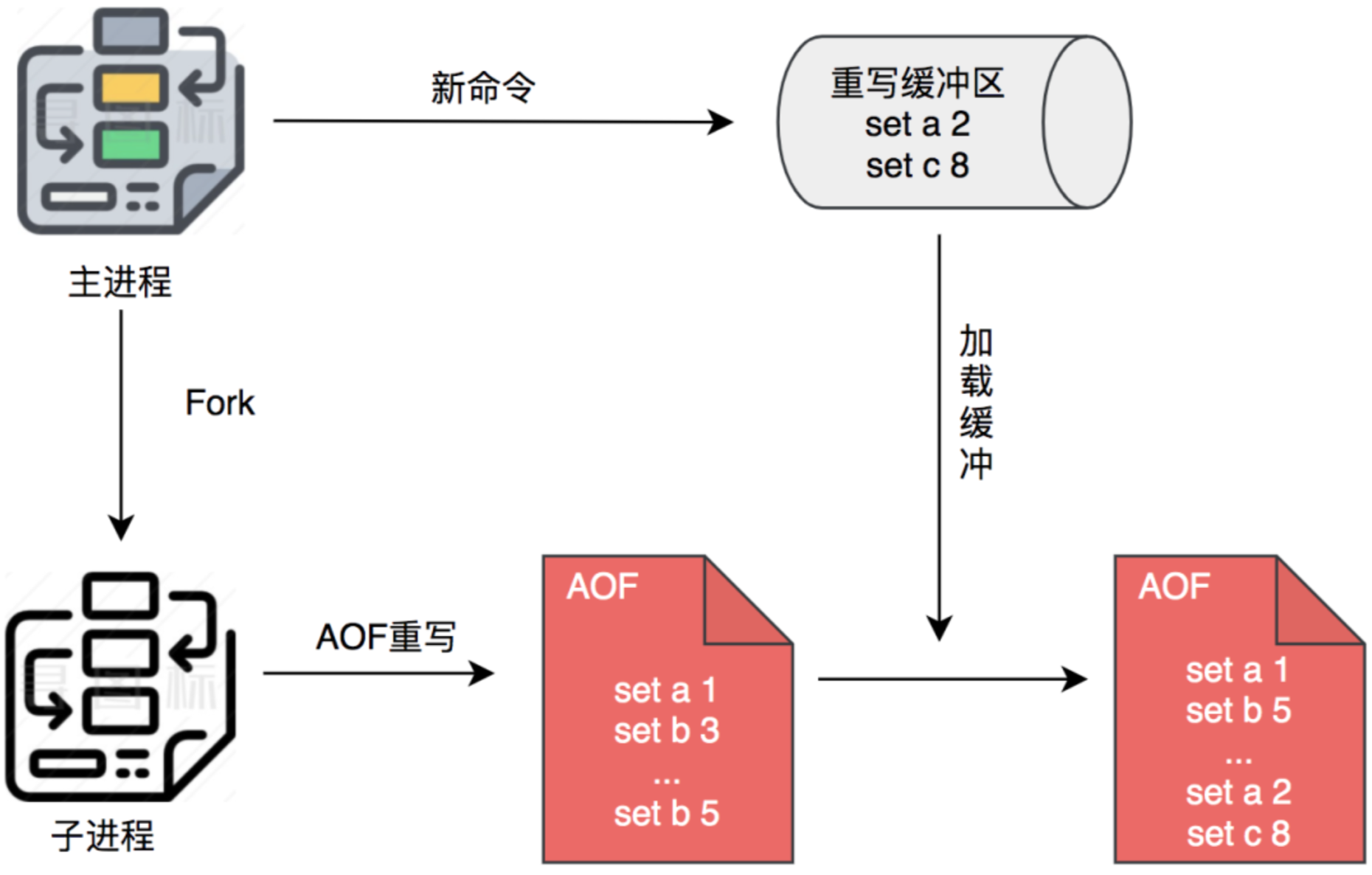
简单描述 AOF 重写流程
- 触发 AOF 重写时,子进程会读取 Redis 数据,写入到 AOF 文件。
- AOF 重写期间的写入操作会存放到 AOF 重写缓冲区。
- 主进程会将缓冲区数据发送给子进程,子进程追加写入 AOF 文件。
AOF 重写你觉得有什么不足之处?
AOF 重写期间的写入操作会入保存两次,AOF缓冲和AOF重写缓冲。
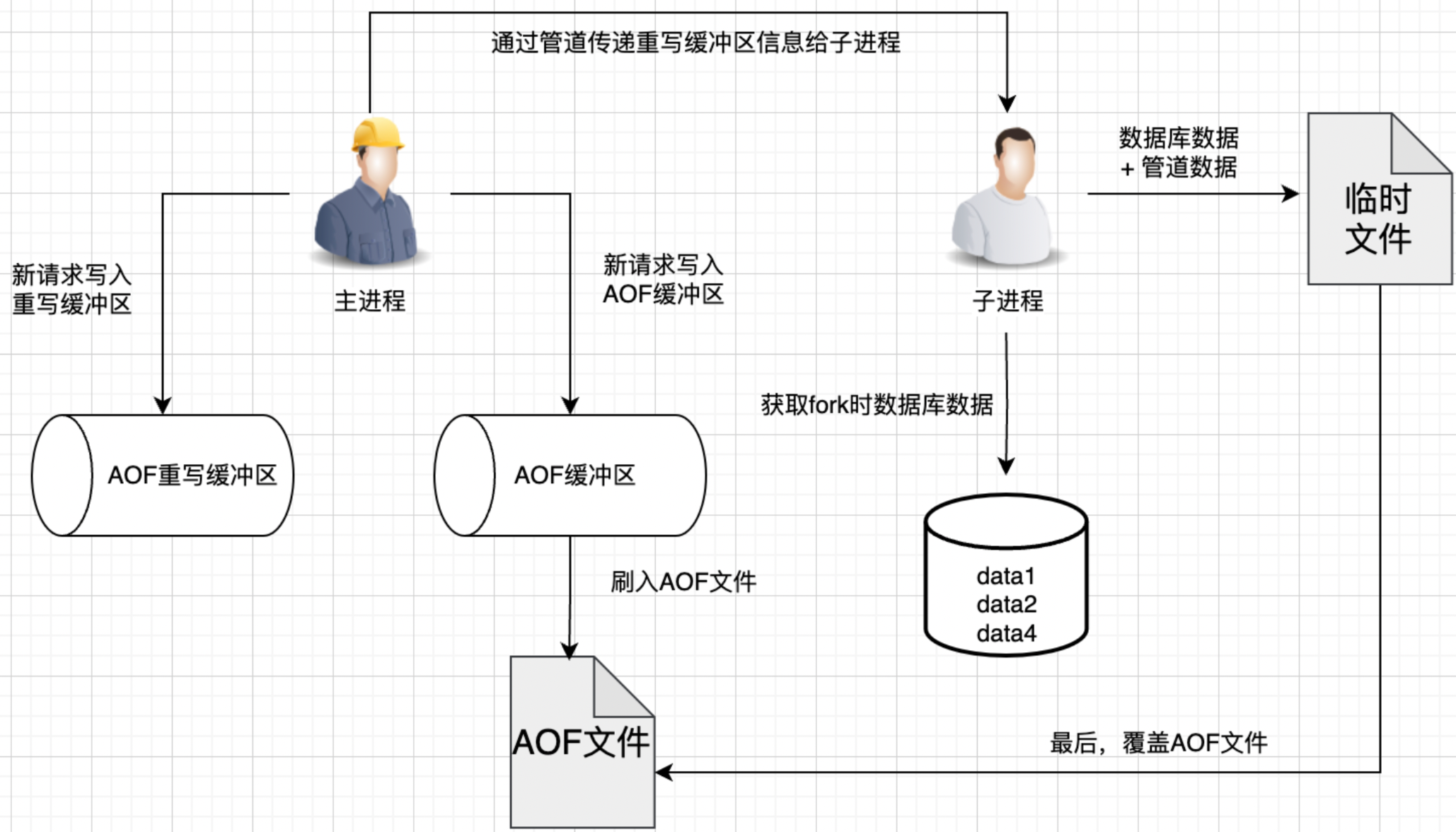
针对 AOF 重写的不足,你有什么优化思路呢?
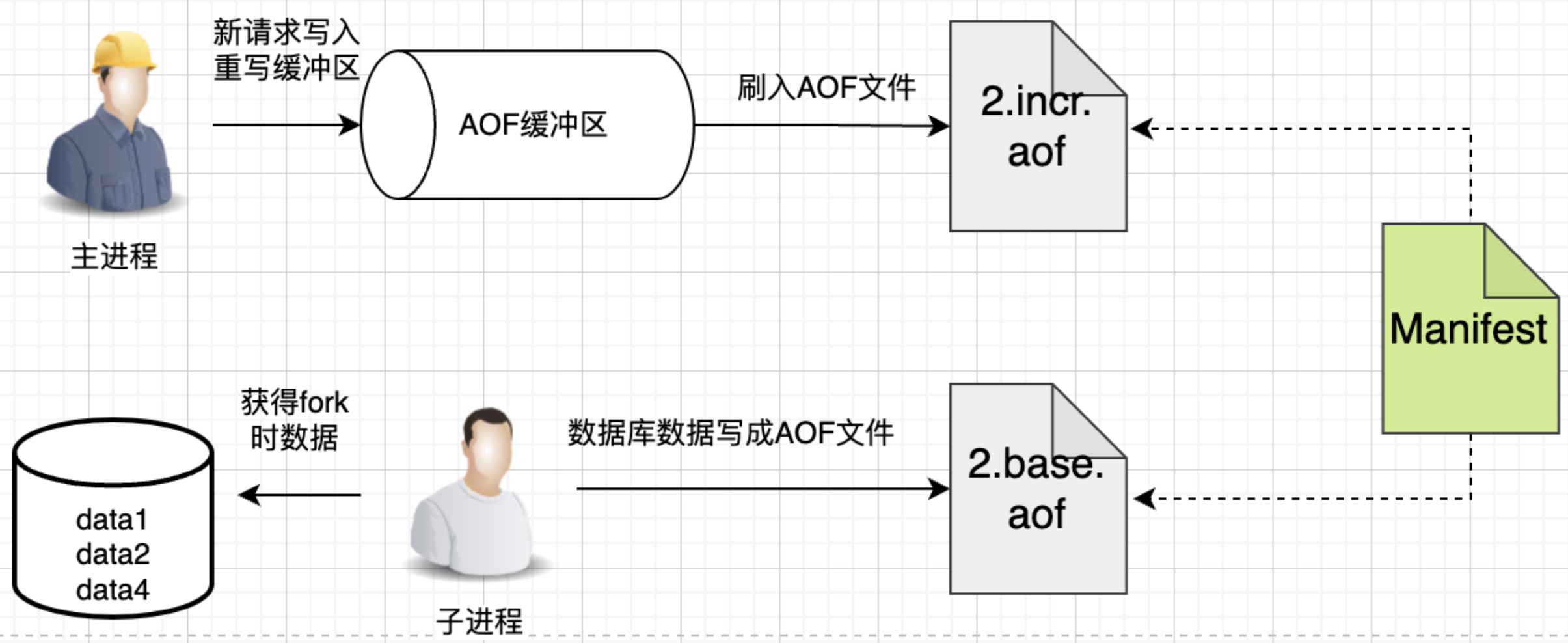
Redis 7.0 以后使用了 MP-AOF 方案。
将 AOF 文件分为 Base AOF 和 Incr AOF。Base AOF 是历史部分,Incr 是新增部分。两者共同组成了重写后的 AOF 文件。
manifest 可以理解成 AOF 的配置清单,记录 AOF 是通过哪几部分组成的。
Redis 过期删除和内存淘汰策略
Redis 是如何删除过期 key 的?
使用 惰性删除 + 定期删除 策略
- 惰性删除:取 key 时查询是否过期
- 定期删除:每隔一段时间删除所有的过期 key
Redis 有几种内存回收策略?
一种是不开启内存回收,内存满了就写入失败。
另一种是开启内存回收,分为两种。其一是基于有过期时间的数据淘汰,有 LRU、LFU、Random、TTL 算法;其二是基于所有数据淘汰,有 LRU、LFU、Random 算法。
- LRU:最久没使用
- LFU:最少使用
- TTL:更早过期的、TTL 最小的
内存回收是什么时候进行的?
每次读写时会检查是否需要回收。
说一下 Redis 的 LRU 算法
LRU 是最近最久未使用,淘汰最久未访问的数据。
Redis 对于 LRU 算法进行了优化。标准 LRU 算法需要维护双向链表,消耗较大。Redis 采用了 LRU 采样,随机取若干个数据,淘汰最久没访问的数据。
什么是 LFU 算法?为什么需要使用 LFU 算法?
LRU 只考虑了访问时间,忽略了访问频率。
LFU 将访问频率加入影响因素中,访问计数同时受上一次访问时间和访问频率的综合影响。
Redis 使用场景
Redis 主要的应用场景是什么?
- 用于存储 Token 或 Session 实现分布式登录
- 进行数据的缓存
- 具有生存时间,适用于验证码或优惠券
- 生成唯一 ID
- 限流
- 排行榜
- 分布式锁
- 消息队列
- 共同关注
- 签到
- UV 计数
- 地理位置相关操作
Redis 缓存是如何使用的?
作为旁路缓存。查询时先查询 Redis,如果 Redis 没有数据则查询 MySQL,并缓存到 Redis。
Redis 做旁路缓存,DB 更新了应该如何操作?
我的项目中在更新数据库后会删除缓存,来提升缓存一致性,并为缓存加入过期时间作为备用。
我还了解过通过订阅 MySQL 的 binlog,异步更新缓存。这种方法和业务完全解耦,但是需要消息队列和消费服务,成本较高。
Redis 做秒杀场景的应用和思路
- 记录库存,通过 Redis 高性能进行库存的记录。
- 作为消息队列,进行流量消峰。
Redis 可以做消息队列吗?
Redis 有一个 List 数据结构,可以作为轻量级消息队列。
如果业务比较轻量级,并且没有引入其他的消息队列,那么 Redis 就可以满足需求。
什么是分布式锁?
用于在分布式系统中控制对共享资源的访问的机制。类比单机环境下多线程的 synchronized。
Redis 分布式锁怎么实现的
使用 setnx 命令,保证只有一个线程能够成功设置值,相当于这个线程获取到了锁。
分布式锁的要点是什么?
- 加锁:使用 setnx 命令,key 是锁名,value 是持有者 id,添加过期时间。
- 解锁:检查是否是自己的锁,然后释放锁。操作需要保证原子性,需要使用 Lua 脚本。
Lua 脚本一定能保证原子性吗?
Lua 本身没有原子性。但是 Redis 是单线程操作,所以 Lua 脚本的执行不会被打断,保证了操作的原子性。
Redis 作为分布式锁的优缺点?
优点:
- 性能高
- Redis 有 setnx 命令,实现简单
- Redis 有集群,避免单点故障
缺点:
- 超时时间不好设置,需要守护线程续约。
- 主从集群是异步复制的,导致不可靠
Redis 集群下如何保证分布式锁的可靠性
使用红锁算法。
客户端和多个独立的Redis节点依次请求申请加锁,如果客户端能够和半数以上的节点成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
缓存穿透是什么?怎么解决?
缓存穿透:用户在请求一个 Redis 和数据库都不存在的数据,请求会直接到达数据库,且不会重建缓存。大量请求会导致大量的数据库压力。
解决方法:
- 缓存空对象:方法简单,但是会造成内存浪费。
- 布隆过滤器:用于查询数据是否存在,对于不存在的数据直接返回,不再查询数据库。
- 限流策略:限制对数据库的请求频率。
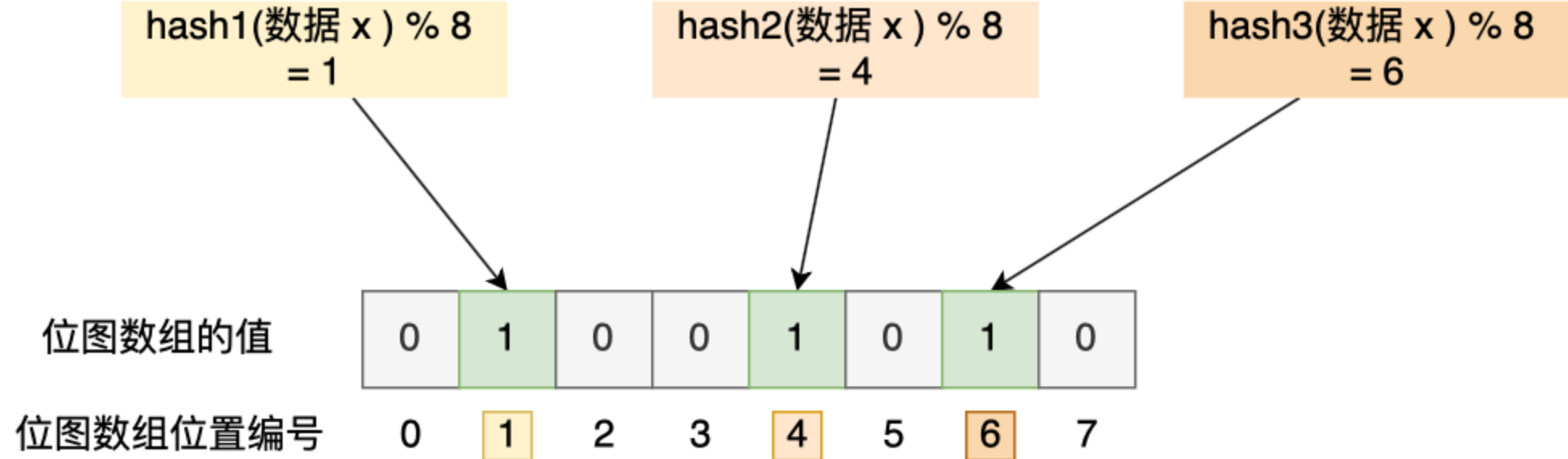
布隆过滤器是如何工作的?
布隆过滤器由位图数组和多个哈希函数组成。
写入数据库中,将数据通过多个哈希函数计算,将每个哈希值都在数组中标记。
在读取数据时,将数据进行哈希计算,如果数组中每个位置对应的都是 1,因为有哈希冲突的可能,所以数据可能存在。但如果不全为 1,那么数据一定不存在。
缓存击穿是什么?怎么解决?
缓存击穿:缓存中某个热点 key 过期了,造成大量请求直接访问数据库。
解决方法:
- 使用互斥锁或分布式锁:只让一个线程去查询数据库并重建缓存。
- 添加多级缓存,比如使用 Caffeine、OpenResty。
- 热点 Key 设置永不过期。
缓存雪崩是什么?怎么解决?
缓存雪崩:大量 Key 同时过期,或 Redis 宕机,导致大量请求直接访问数据库。
解决方法:
- 给不同的 Key 设置不同的 TTL 值:避免大量 Key 同时过期重建。
- 使用互斥锁或分布式锁:只让一个线程去查询数据库并重建缓存。
- 缓存预热:在非高峰期提前更新缓存
- 添加多级缓存:使用 Caffeine、OpenResty。
- 使用 Redis 集群:提高 Redis 的可用性
Redis 集群
Redis 集群架构有几种?
主从集群、哨兵集群、切片集群。
- 主从集群:一台作为主节点,其余为从节点。主节点处理读写,从节点只读,主节点将数据异步同步给从节点。
- 哨兵集群:实现故障恢复的功能,哨兵监控主节点。
- 切片集群:解决数据量较大的问题,将数据分布在多个节点上,可以降低对单个节点的依赖,提高读写性能。
主从节点是如何同步的?
分为两种:全量同步、增量同步
- 全量同步:首次同步。需要将主节点所有数据同步到从节点。
- 增量同步:全量同步后,当主节点数据发生修改,会同步给从节点。
主从模式是同步复制还是异步复制?
异步
主节点收到写命令之后,先写到内部的缓冲区,然后再异步发送给从节点。
Redis 主从同步的优缺点?
优点:读写分离,提高性能
缺点:占用较多内存,存在单点故障
哨兵模式是什么?
哨兵模式主要解决主从集群存在主节点单点故障的问题。
哨兵会监控主节点状态,当主节点宕机时,会选举一个哨兵节点作为主节点。
哨兵模式的优缺点是什么?
优点:保证 Redis 服务的高可用
缺点:主从模式单点风险高、主从切换可能会造成数据丢失、数据量不能太大
Redis 的哈希槽是什么?
用于分片集群中。
Redis 集群有 2^14 个哈希槽,对每个 key 通过哈希运算决定放到哪个槽。每个 Redis 节点负责一部分的哈希槽。